How I Created a Semantic Cache Library for AI
Originally published on Dev.to on October 27, 2025.
Read the Dev.to version

Have you ever wondered why LLM apps get slower and more expensive as they scale, even though 80% of user questions sound pretty similar? That’s exactly what got me thinking recently: why are we constantly asking the model the same thing?
That question led me down the rabbit hole of semantic caching, and eventually to building VCAL (Vector Cache-as-a-Library), an open-source project that helps AI apps remember what they’ve already answered.
The “Eureka!” Moment
It started while optimizing an internal support chatbot that ran on top of a local LLM. Logs showed hundreds of near-identical queries:
“How do I request access to the analytics dashboard?”
“Who approves dashboard access for my team?”
“My access to analytics was revoked — how do I get it back?”
Each one triggered a full LLM inference: embedding the query, generating a new answer, and consuming hundreds of tokens even though all three questions meant the same thing.
So I decided to create a simple library that would embed each question, compare it to what was submitted earlier, and if it’s similar enough, return the stored answer instead of generating an LLM response, all this before asking the model.
I wrote a prototype in Rust — for performance and reliability — and designed it as a small vcal-core open-source library that any app could embed.
The first version of VCAL could:
- Store and search vector embeddings in RAM using HNSW graph indexing
- Handle TTL and LRU evictions automatically
- Save snapshots to disk so it could restart fast
Later came VCAL Server, a drop-in HTTP API version for teams that wanted to cache answers across multiple services while deploying it on-prem or in a cloud.
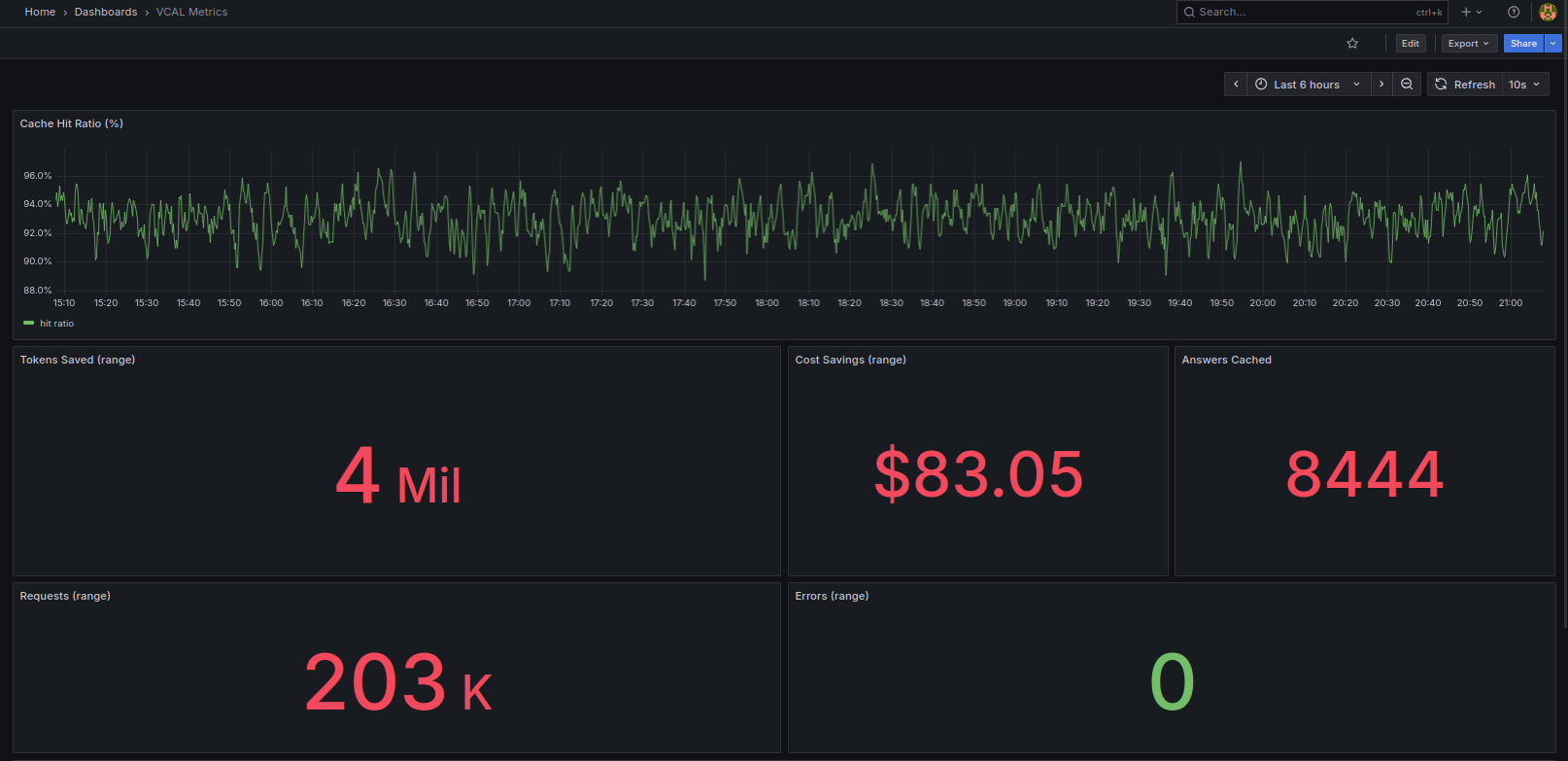
What It Feels Like to Use
Unlike a full vector database, VCAL isn’t designed for long-term storage or analytics. I didn’t want to build another vector database.
VCAL is intentionally lightweight. It is a fast, in-memory semantic cache optimized for repeated LLM queries.
Integrating VCAL takes minutes.
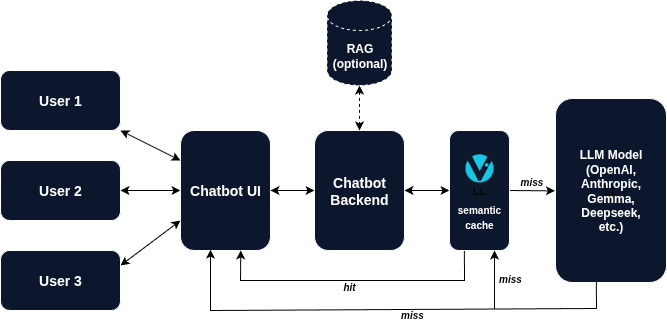
Instead of calling the model directly, you send your query to VCAL first.
If a similar question has been asked before — and the similarity threshold can be tuned — VCAL returns the answer from its cache in milliseconds.
If it’s a new question, VCAL asks the LLM, stores the result, and returns it.
Next time, if a semantically similar question comes in, VCAL answers instantly.
It’s like adding a memory layer between your app and the model — lightweight, explainable, and under your full control.
Lessons Learned
- LLMs love redundancy. Once you start caching semantically, you realize how often people repeat the same question with different words.
- Caching semantics ≠ caching text. Cosine similarity and vector distances matter more than exact matches.
- Performance scales beautifully. A well-tuned cache can handle thousands of lookups per second, even on modest hardware.
- It scales big. A single VCAL Server instance can comfortably store and serve up to 10 million cached answers in memory, depending on embedding dimensions and hardware.
What’s Next
We’re now working on a licensing server, enterprise snapshot formats, and RAG-style extensions, so teams can use VCAL not just for Q&A caching, but as the foundation for private semantic memory.
If you’re building AI agents, support desks, or knowledge assistants, you’ll likely benefit from giving your system a brain that remembers.
You can explore more at vcal-project.com - try the free 30-day Trial Evaluation of VCAL Server or jump into the open-source vcal-core version on GitHub.
Thanks for reading!
If this resonates with you, please drop a comment. I’d love to hear how you’re approaching caching and optimization for AI apps.