What Actually Matters When You Try to Reduce LLM Costs
Originally published on Medium.com on April 5, 2026.
Read the Medium.com version
After publishing the first release of AI Cost Firewall, I thought the hard part was done.
The idea was simple and it worked immediately: avoid sending duplicate or semantically similar requests to the LLM, and you reduce cost.
I described that initial approach in more detail here: How to Reduce OpenAI API Costs with Semantic Caching
And it did work.
But once I started pushing it further — adding more metrics, handling edge cases, running real traffic through it — it became clear that the initial idea was only a small part of the problem.
Reducing LLM cost is not just about caching. It’s about understanding where the cost actually comes from, what “savings” really mean, and what begins to break when a system moves from a controlled demo into something closer to production.
The First Insight Still Holds
The original observation hasn’t changed, and neither has the core architecture. The system still solves the same underlying problem.
- Users repeat themselves.
- Applications repeat themselves.
- Agents repeat themselves.
Often the wording changes slightly, but the intent remains the same. From the model’s perspective, however, every variation is a brand new request. And every request has a cost.
So yes — caching works. It reduces cost immediately, often without any changes to the application itself.
But that’s only the surface. The deeper questions only appear once you try to rely on it.
The First Misconception: “Caching Is Free”
In the beginning, the results looked almost too good.
In a demo environment, exact cache hits dominated. When a request hit the cache, it meant no API call, no tokens, and almost zero latency. It felt like pure gain, as if cost reduction came with no trade-offs.
That illusion disappears the moment you introduce semantic caching properly. Because semantic caching requires embeddings.
To determine whether two requests are similar, you first need to convert them into vectors. That means calling an embedding model, storing the result, and comparing it against existing data. Only then can you decide whether to reuse a response or forward the request to the LLM.
And embeddings are not free.
At that point, the equation changes:
Net savings = avoided LLM cost − embedding cost
This is where things become more delicate.
If your similarity threshold is too low, you generate embeddings too often. If your traffic is highly unique, most of those embeddings never lead to a cache hit. If your embedding model is expensive, the optimization starts working against you.
What initially looked like a simple cost reduction mechanism becomes something that requires careful balance.
That was the moment when the project stopped being just a clever shortcut and started behaving like a system that needs tuning.
Where the Savings Actually Come From
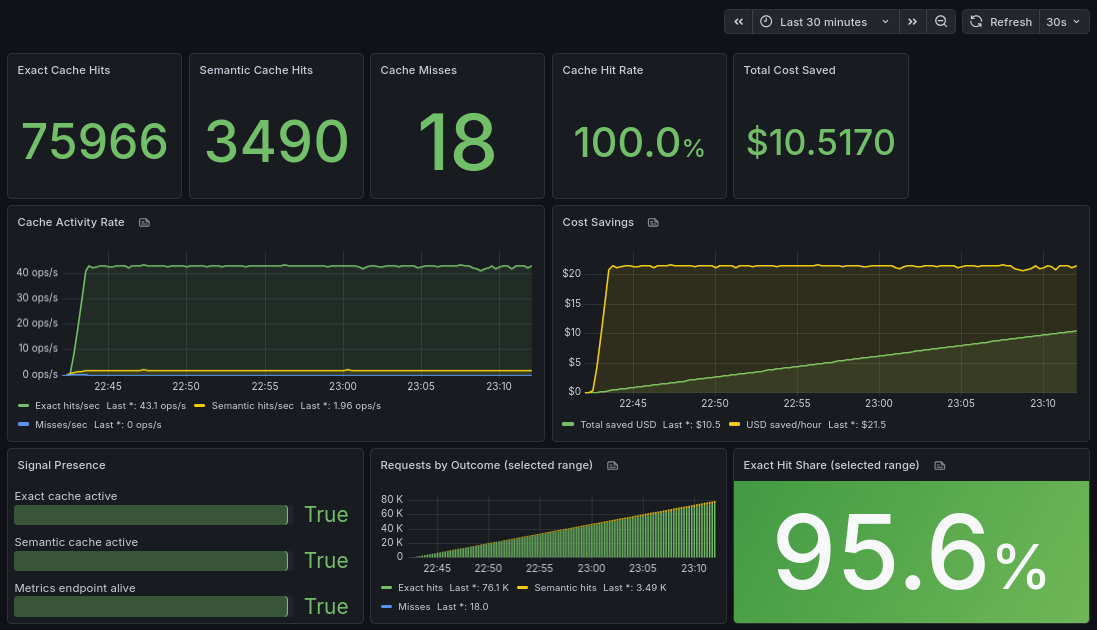
Looking at real metrics changed another assumption.
Intuitively, semantic caching feels like the main feature. It’s the “intelligent” part of the system. But in practice, most of the savings come from something much simpler — exact matches.
A surprisingly large portion of traffic is not just similar — it is identical. The same prompt appears again and again, sometimes minutes apart, sometimes hours later. Once you see it in real data, it’s hard to ignore.
Semantic caching still matters, but its role is different. It extends the coverage rather than forming the base.
Without exact caching, the system loses most of its immediate impact. Without semantic caching, you miss additional opportunities. But they are not equal contributors, and treating them as such leads to wrong expectations.
What Breaks in Real Usage
As soon as real traffic enters the system, subtle issues begin to surface.
One of the first is payload size.
LLM requests tend to grow over time. Prompts accumulate context, system messages expand, conversation history becomes longer. In some cases, payloads become unexpectedly large — either naturally or intentionally.
Without limits, a single request can consume disproportionate resources. What seemed like a minor edge case quickly turns into something that needs explicit control.
Another issue is validation.
If you accept any model name, any payload structure, and any input format, your system remains flexible but your metrics lose meaning. Cost calculations become inconsistent, comparisons stop being reliable, and “savings” become difficult to interpret.
Adding strict validation changes that. It makes the system more predictable, but also more opinionated.
At that point, it is no longer just a transparent proxy. It becomes a controlled gateway. And that shift is intentional.
It’s worth noting that this layer is not a security firewall in the traditional sense. It does not attempt to detect malicious prompts, prevent prompt injection, or enforce content policies. Those concerns belong to the application layer, where context, user intent, and business logic are better understood. The goal here is different: to control cost, reduce unnecessary requests, and make LLM usage more predictable.
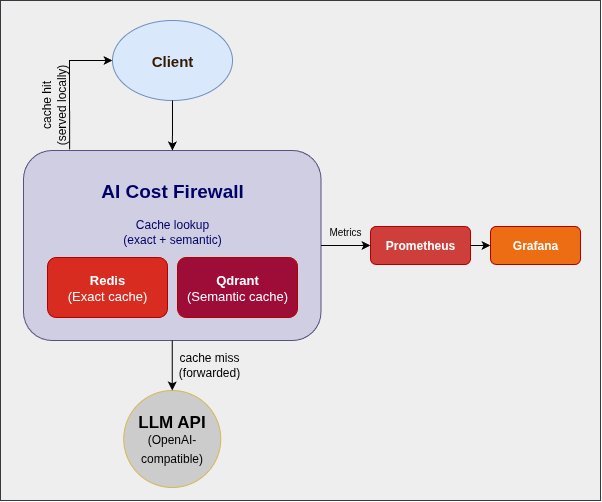
Architecture Matters More Than It Seems
From the outside, the architecture still looks simple. One layer in front of the LLM, minimal components, no intrusive changes to the application.
But over time, the reasoning behind each choice becomes more important.
- Redis handles exact matches because it is fast and predictable.
- Qdrant supports semantic search efficiently without adding unnecessary complexity.
- Rust ensures that this layer can sit in the request path without introducing latency or instability.
Individually, these are straightforward decisions.
Together, they define whether the system can operate reliably under load. Because once this layer becomes part of the critical path, it is no longer optional. If it slows down, everything slows down. If it fails, everything fails.
At that point, optimization is no longer the only goal. Stability becomes equally important.
The Difference Between Demo Traffic and Reality
It is easy to produce impressive results in a controlled environment.
- high cache hit rates
- clear cost savings
- clean, predictable behavior
But those results are shaped by the input.
Real systems behave differently. There are always new queries, unexpected variations, and edge cases that were not part of the initial design. You never reach 100% cache hits — and that’s not a failure.
A healthy system still generates misses. It still calls the model. It still adapts to new inputs.
The goal is not to eliminate LLM usage entirely. The goal is to eliminate unnecessary usage. That distinction becomes much more important once you move beyond a demo.
Where This Is Going
What started as a simple way to avoid duplicate requests is gradually evolving into something broader.
It is no longer just about caching. It becomes a control layer for how LLMs are used:
- cost visibility
- request validation
- provider abstraction
- traffic control
Caching is still at the center, but it is no longer the whole story. It is the entry point into a larger set of concerns that appear once LLM usage grows.
Final Thoughts
The original idea was simple: Don’t pay twice for the same answer.
That still holds. But applying that idea in a real system reveals a different challenge.
The difficult part is not avoiding the call. It is understanding when avoiding it actually makes sense. Because cost optimization, in practice, is not just about reducing usage. It is about understanding your system well enough to reduce costs in the right way.
You can explore the project here: