Not All “AI Security” Is the Same: Application Layer vs AI Cost Firewall
Originally published on Medium.com on April 22, 2026.
Read the Medium.com version
As LLM applications move from demos into production, many teams double down on one thing: prompt security. They refine system prompts, add guardrails, introduce moderation, and carefully control how users interact with the model. And yet, once real traffic arrives, something unexpected happens.
At first, everything works. The demo is smooth, responses are fast, costs are negligible.
But soon real usage begins. Costs spike, latency becomes inconsistent, errors become harder to understand, deployments start affecting live requests in subtle ways.
Nothing is obviously broken, but the system no longer feels predictable.
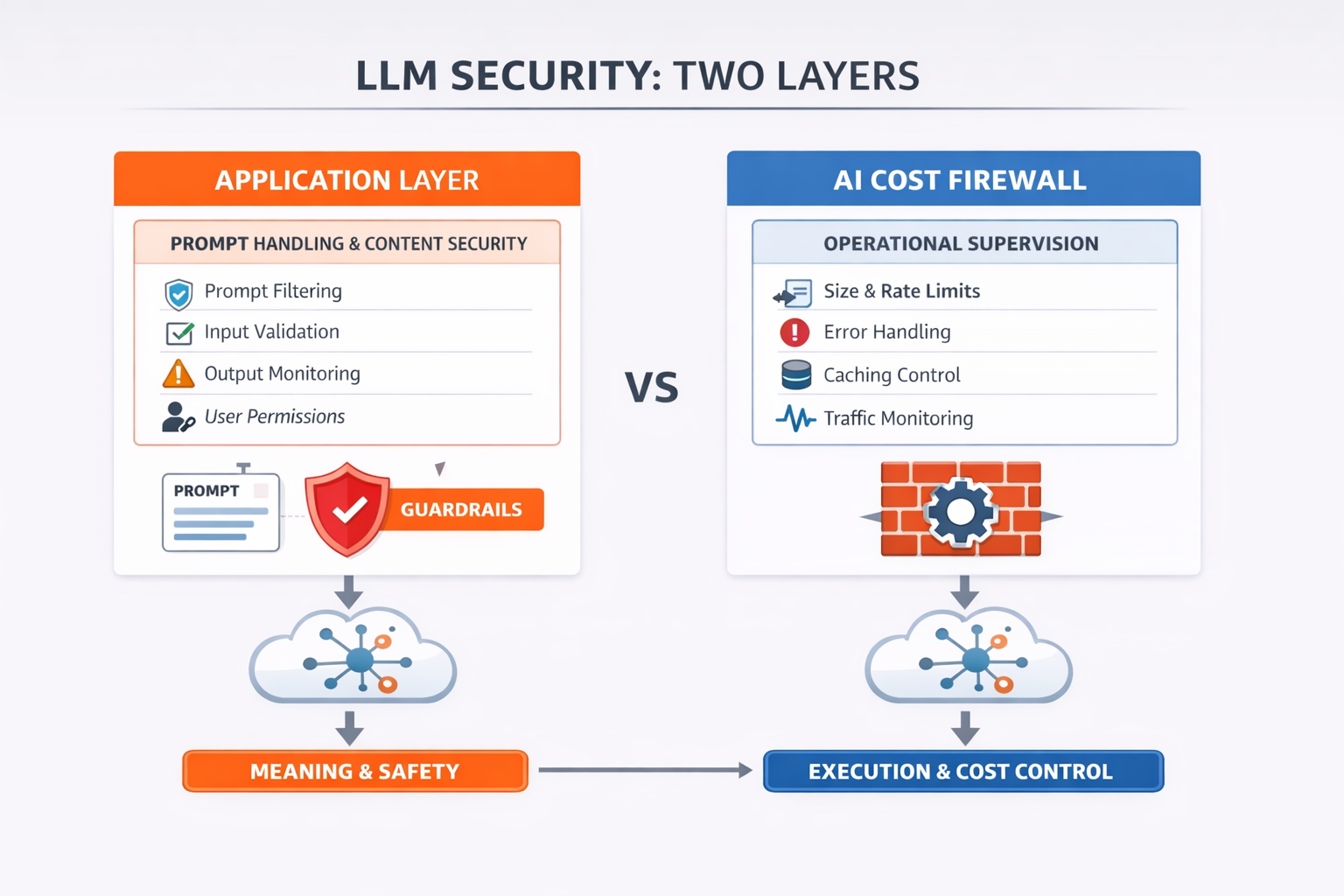
The Application Layer: Controlling Meaning and Behavior
The application layer is where the logic of an AI product lives. It defines how prompts are constructed, how users interact with the system, and what the model is allowed to do.
This is where most teams focus first — and for good reason. Here, you are dealing with meaning, intent, and safety.
At this layer, the focus is on controlling what the model is allowed to do. In practice, that translates into questions like:
- Can a user manipulate the model through prompt injection?
- Can sensitive data leak through responses?
- Are outputs aligned with policy and expectations?
To solve this, teams build a combination of structural and defensive controls:
- Structured prompts and system messages
- Input validation and sanitization
- Output filtering and moderation
- Access control and business logic
These mechanisms are essential. Without them, the system is exposed at the semantic level.
In short, the application layer protects what the model means and does.
The Missing Layer: Controlling Execution and Behavior Under Load
However, there is another category of problems that has nothing to do with meaning. They emerge only when the system is under real conditions.
Here are the most usual ones:
- Prompts gradually become larger and heavier
- Similar requests are repeated again and again
- Upstream providers introduce latency or intermittent failures
- Errors return in inconsistent formats
- Deployments interrupt in-flight requests
These are not prompt problems. They are system behavior problems. The application layer answers: “Is this prompt safe?” The next layer answers: “Should this request exist at all?”
This is where the AI Cost Firewall layer comes in.
Two distinct layers in LLM systems: the application layer controls meaning and safety, while the AI Cost Firewall controls execution, cost, and reliability.
Sitting between the application and the LLM provider, it acts as a control plane for LLM traffic. Its role is not to understand the prompt, but to ensure that every request is handled in a controlled, predictable, and observable way.
At this layer, the focus shifts to:
- How large is the request?
- Should this request even reach the provider?
- Is this a duplicate or semantically similar request?
- Did the upstream fail, timeout, or respond incorrectly?
- What happens if the system is shutting down?
To answer these, the AI Cost Firewall introduces the following guardrails:
- Prompt size supervision and request validation
- Error classification and normalized responses
- Timeout handling and upstream protection
- Exact and semantic caching
- Readiness checks and graceful shutdown behavior
This layer protects how the system executes and consumes resources.
Why These Layers Are Not Interchangeable
It’s tempting to think that strong application-layer security is enough.
The difference becomes obvious when you look at what each layer is actually responsible for.
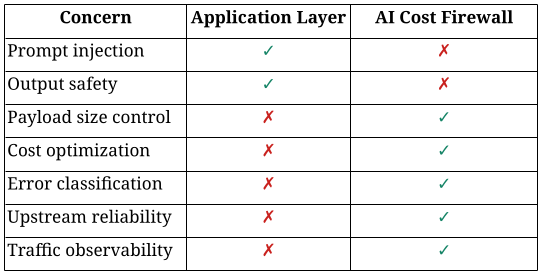
Two layers of LLM systems: controlling meaning vs controlling behavior
A perfectly secured prompt can still result in:
- A 2MB payload that strains your system
- Thousands of repeated requests driving unnecessary cost
- Silent upstream timeouts with no clear diagnostics
In other words, semantic safety does not guarantee operational stability.
A Familiar Pattern, Just Not Yet in AI
If this separation feels unfamiliar, it’s only because LLM systems are still new.
In traditional web architecture, this distinction is well understood:
- the application handles authentication, authorization, and business logic
- the infrastructure layer (reverse proxy, API gateway) handles request validation, rate limiting, retries, and observability
In that world, tools like Nginx became essential — not because they understand your business logic, but because they control how requests flow through the system.
The same pattern is now emerging in AI systems.
AI Cost Firewall plays a role similar to Nginx but for LLM traffic.
It does not interpret prompts or enforce business rules. Instead, it ensures that every request is well-formed, controlled, observable, and efficient before it reaches the model.
And just like in web systems, skipping this layer might work in a demo, but it rarely holds up in production.
No one would deploy a production system that sends raw traffic directly to back-end services without passing through a control layer. And yet, this is exactly how many LLM applications operate today.
What Changes in Production
In early prototypes, everything seems fine. Traffic is low, prompts are short, and errors are rare.
However, production changes the situation completely:
- Prompts accumulate context and silently grow
- Users repeat similar queries in slightly different forms
- Costs scale faster than usage
- Failures become harder to classify and debug
These issues don’t break the system immediately. They degrade it gradually, until behavior becomes unpredictable.
This is precisely the gap the AI Cost Firewall layer is designed to address.
The Key Insight
LLM security is not just about safe prompts. It’s about safe system behavior under real conditions.
The application layer ensures the model behaves correctly. The AI Cost Firewall ensures the system behaves reliably.
Both are required to move from a working demo to a production-grade system.
Final Thought
Most teams start by asking: “How do we control what the model says?”
But in production, a more important question emerges: “How do we control what the system does under real conditions?”
That’s where the second layer becomes essential.